TVM Auto-scheduler (又名 Ansor) 简介
随着模型规模、算子多样性和硬件异构性的增长,优化深度神经网络的执行速度变得极其困难。从计算的角度来看,深度神经网络只是由一层又一层的张量计算组成。这些张量计算,例如 matmul 和 conv2d,可以很容易地用数学表达式来描述。然而,在现代硬件上为它们提供高性能的实现可能非常具有挑战性。我们必须应用各种底层优化并利用特殊的硬件内在函数才能实现高性能。构建像 CuBLAS、CuDNN、oneMKL 和 oneDNN 这样的线性代数和神经网络加速库需要巨大的工程投入。
如果我们只需编写数学表达式,然后让某种神奇的东西将它们转化为高效的代码实现,我们的生活将会轻松得多。三年前,深度学习编译器 TVM 及其搜索模块 AutoTVM 的构建是朝着这个目标迈出的第一步。AutoTVM 采用基于模板的搜索算法来为给定的张量计算找到高效的实现。然而,它是一种基于模板的方法,因此仍然需要领域专家为每个平台上的每个算子实现一个重要的手动模板。如今,TVM 代码仓库中用于这些模板的代码超过 1.5 万行。除了非常难以开发之外,这些模板通常具有效率低下且有限的搜索空间,使得它们无法实现最佳性能。
为了解决 AutoTVM 的局限性,我们启动了 Ansor 项目,旨在开发一个完全自动化的自动调度器,用于为张量计算生成代码。Ansor 自动调度器仅以张量表达式作为输入,并在没有手动模板的情况下生成高性能代码。我们在搜索空间构建和搜索算法方面进行了创新。因此,该自动调度器能够以更自动化的方式,在更短的搜索时间内实现更好的性能。
Ansor 自动调度器现在已作为 tvm.auto_scheduler 包集成到 Apache TVM 中。这是由加州大学伯克利分校、阿里巴巴、AWS 和 OctoML 的合作者共同努力的成果。TVM 网站 [1] 上提供了针对英特尔 CPU、ARM CPU、英伟达 GPU 和 Mali GPU 的详细教程。在这篇博文中,我们将给出高层次的介绍,并展示一些基准测试结果。
系统概述
AutoTVM vs 自动调度器

表 1 比较了在 AutoTVM 和自动调度器中为算子生成代码的工作流程。在 AutoTVM 中,开发人员必须经过三个步骤。在步骤 1 中,开发人员必须使用 TVM 的张量表达式语言编写计算定义。这部分相对容易,因为 TVM 的张量表达式语言看起来就像数学表达式。在步骤 2 中,开发人员必须编写一个调度模板,这通常包含 20-100 行棘手的 DSL 代码。这部分需要目标硬件架构和算子语义方面的领域专业知识,因此非常困难。最后一步,步骤 3,由搜索算法自动完成。
在自动调度器中,我们通过自动搜索空间构建消除了最困难的步骤 2,并通过更好的搜索算法加速了步骤 3。通过进行自动搜索空间构建,我们不仅消除了巨大的人工工作量,而且还能够探索更多的优化组合。这种自动化并非没有代价,因为我们仍然需要设计规则来生成搜索空间。然而,这些规则非常通用。它们基于对张量表达式的静态分析。我们只需要设计一些通用规则一次,就可以将它们应用于深度学习中几乎所有的张量计算。
搜索过程
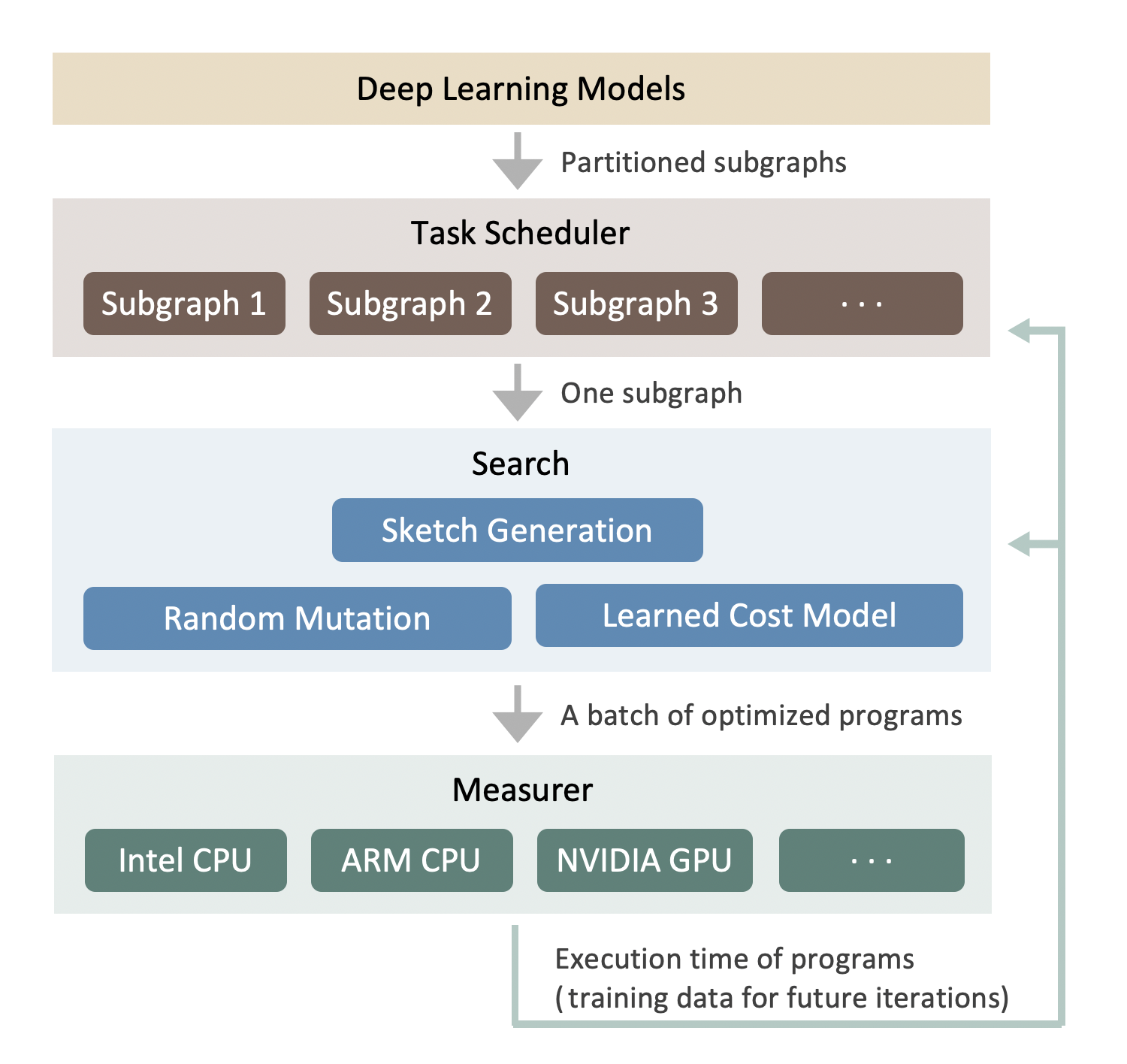
图 1 展示了自动调度器在优化整个神经网络时的搜索过程。系统以深度学习模型作为输入。然后,它使用 Relay 的算子融合 pass 将大型模型划分为小的子图。利用任务调度器为优化许多子图分配时间资源。在每次迭代中,它会选择一个最有潜力提高端到端性能的子图。对于这个子图,我们分析其张量表达式并为其生成多个草图。然后,我们使用带有学习到的成本模型的进化搜索来获得一批优化的程序。优化的程序被发送到实际硬件进行测量。当测量完成后,分析结果将用作反馈来更新系统的所有组件。这个过程会迭代重复,直到优化收敛或我们的时间预算用完。更多技术细节可以在我们的论文 [3] 和我们的代码中找到。
值得注意的是,由于自动调度器从头开始生成调度,它重用了 TOPI 中现有的计算定义,而不是调度模板。
基准测试结果
在本节中,我们将对 AutoTVM 和自动调度器的性能进行基准测试。CPU 基准测试在 AWS c5.9xlarge 上完成,它配备了英特尔 18 核 skylake 8124-m CPU。GPU 基准测试在 AWS g4dn.4xlarge 上完成,它配备了英伟达 T4 GPU。所有基准测试代码、原始数据、调优日志都可以在这个仓库 [2] 中找到。
生成的代码的性能
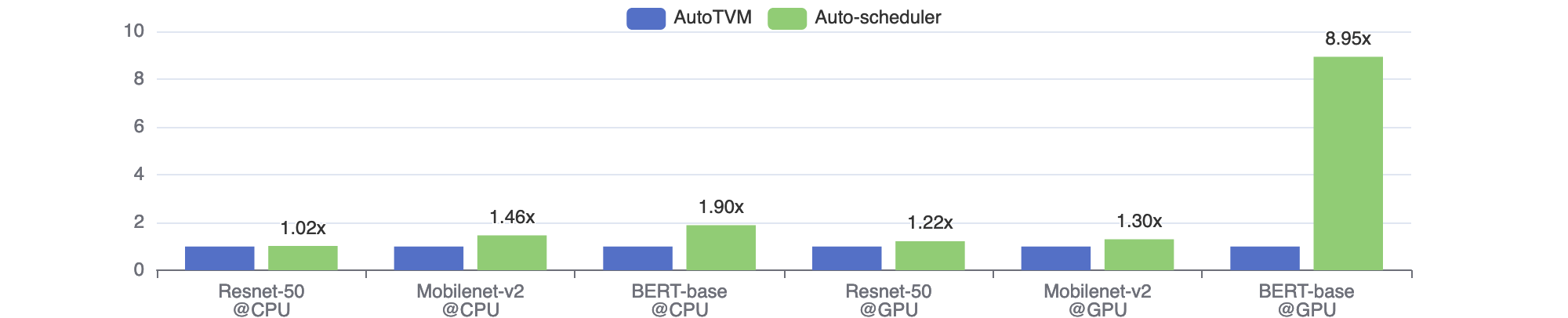
我们对三个网络进行了 fp32 单批次推理延迟的基准测试。图 2 显示了自动调度器相对于 AutoTVM 的相对加速。我们可以看到,在所有情况下,自动调度器的性能都优于 AutoTVM,加速比为 1.02 倍到 8.95 倍。这是因为自动调度器探索了更大的搜索空间,其中涵盖了 TOPI 手动模板中遗漏的更有效的优化组合。BERT-base@GPU 是一个极端案例,其中手动模板设计得非常糟糕。换句话说,密集层的手动模板在 BERT 模型中的形状下表现不佳。
搜索时间
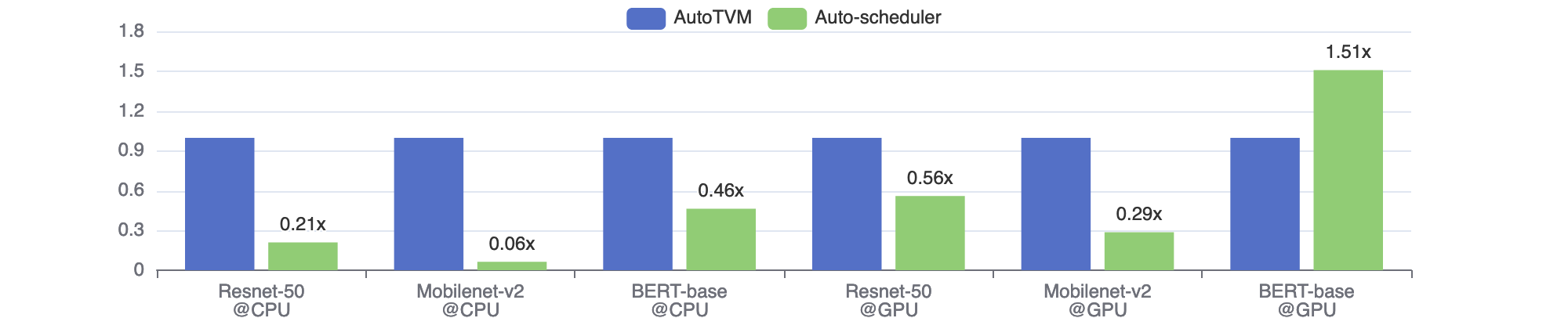
众所周知,基于搜索的方法可能非常耗时,因此我们也关心搜索时间。通常需要几个小时才能让单个神经网络的搜索收敛。图 3 比较了 AutoTVM 和自动调度器的搜索时间。尽管自动调度器具有更大的搜索空间,但在大多数情况下,它收敛所需的时间要少得多。这主要是因为自动调度器具有更好的成本模型和任务调度器。
更多结果
上面的仓库作为 TVM 的内部基准测试工具,因此它只比较了最新的 AutoTVM 和 AutoScheduler。您可以在我们的论文 [3] 中找到更多库和后端的测试结果。最近,这篇博客文章 [4] 还在 Apple M1 芯片上尝试了自动调度器,并获得了一些良好的结果。
结论
我们构建了 TVM 自动调度器,一个自动为张量表达式生成高性能代码的系统。与前身 AutoTVM 相比,自动调度器不需要手动模板。此外,自动调度器能够在更短的时间内生成性能更好的调度。我们通过在搜索空间构建和搜索算法方面的创新实现了这一点。
我们对自动调度器目前的性能感到兴奋。未来,我们有兴趣扩展自动调度器的能力,以更好地支持稀疏算子、低精度算子和动态形状。
链接
[1] 教程:https://tvm.apache.org/docs/tutorials/index.html#autoscheduler-template-free-auto-scheduling
[2] 基准测试仓库:https://github.com/tlc-pack/TLCBench
[3] OSDI 论文:Ansor : 为深度学习生成高性能张量程序
[4] 在 Apple M1 芯片上的结果:https://medium.com/octoml/on-the-apple-m1-beating-apples-core-ml-4-with-30-model-performance-improvements-9d94af7d1b2d。