自带数据类型:在 TVM 中启用自定义数据类型探索
在这篇文章中,我们介绍了自带数据类型框架,该框架支持在 TVM 中使用自定义数据类型。
简介
在设计加速器时,一个重要的决定是如何在硬件中近似表示实数。这个问题有一个长期存在的行业标准解决方案:IEEE 754 浮点标准。1 然而,当试图通过构建高度专业化的设计来最大限度地发挥硬件性能时,使用通用的 IEEE 754 浮点数是否有意义?如果我们知道工作负载的数值要求,我们是否可以构建更小、更快或更节能的数据类型?答案是肯定的!研究人员已经开始在学术界和工业界的加速器设计中尝试新的数据类型。例如,谷歌的张量处理单元(TPU)使用了 bfloat 类型:一种被截断为 16 位的单精度 IEEE 浮点数。由于许多深度学习工作负载的数值要求较为宽松,这种截断通常对模型精度没有影响,同时可以立即将存储成本降低一半。23
然而,在研究人员开始为其数据类型构建硬件之前,他们首先需要确定他们的数据类型在他们关心的工作负载中的数值行为。这通常首先需要构建其数据类型的软件模拟版本(例如 Berkeley SoftFloat 或 libposit),然后将数据类型直接嵌入到工作负载中,以查看工作负载在使用该数据类型时的性能。更好的是将数据类型直接集成到编译器本身中,以便可以将许多不同的工作负载编译为使用该数据类型。这两种途径都可能很繁琐,而后一种途径通常会因现代编译器的大小和复杂性而变得难以管理。GitHub 上的一个例子 展示了有人将 posit 数据类型 hack 到 TensorFlow 中的情况。结果是 237 次提交,添加了近 6000 行代码,并修改了代码库中 200 多个文件——而这仅仅是添加一种数据类型!对于许多研究人员来说,这种工作量是令人望而却步的。
为了解决这些问题,我们提出了自带数据类型框架。该框架通过允许用户将其模拟的数据类型插入 TVM,从而轻松探索深度学习工作负载中的新数据类型。与上述 posits-in-Tensorflow 示例(在编译器中启用单个新数据类型)不同,自带数据类型框架支持各种各样的用户定义类型。
自带数据类型
自带数据类型框架的目标是使用户能够使用自定义数据类型运行深度学习工作负载。在自带数据类型框架中,“数据类型”是指标量类型:例如 float 或 uint。我们不处理更复杂的数据格式,例如 块浮点 或 Intel 的 Flexpoint。此外,我们仅声明支持这些标量数据类型的软件模拟版本;我们不明确支持在自定义数据类型硬件上编译和运行。
TVM 中的每个张量都分配有一个类型代码,该代码定义了张量内标量的数据类型。其中一些类型代码在 TVM 中具有硬编码的含义,映射到常见的数据类型,例如 int 和 float。但是,绝大多数类型代码都未使用。自带数据类型框架允许用户声明这些未使用的类型代码,并在运行时添加他们自己的新数据类型。
该框架实现为一个注册表,与 TVM 的常规数据类型工具并行存在。用户与数据类型注册表交互主要有两种方式:首先,数据类型注册,其次,降低函数注册。这些步骤分别类似于数据类型的声明和实现。
请注意,这篇文章中引用的所有代码都基于 TVM 仓库的 master 分支提交 4cad71d。我们将使用一个示例 posit 数据类型,该类型可以在 src/target/datatype/posit/posit-wrapper.cc 下找到,并且可以在 TVM 中使用 USE_BYODT_POSIT 标志编译。4
数据类型注册
要注册数据类型,用户需要为数据类型分配一个名称和一个类型代码,其中类型代码来自可用于自定义数据类型的未使用类型代码范围。
tvm.target.datatype.register('posit', 150)
上面的代码注册了类型代码为 150 的 'posit' 数据类型。此注册步骤允许 TVM 解析使用自定义类型的程序
x = relay.var('x', shape=(3, ), dtype='float32')
y = relay.var('y', shape=(3, ), dtype='float32')
x_posit = relay.cast(x, dtype='custom[posit]16')
y_posit = relay.cast(y, dtype='custom[posit]16')
z_posit = x_posit + y_posit
z = relay.cast(z_posit, dtype='float32')
program = relay.Function([x, y], z)
print(program)
# v0.0.4
# fn (%x: Tensor[(3), float32], %y: Tensor[(3), float32]) {
# %0 = cast(%x, dtype="custom[posit]16");
# %1 = cast(%y, dtype="custom[posit]16");
# %2 = add(%0, %1);
# cast(%2, dtype="float32")
# }
上面的程序将 float32 输入 x 和 y 转换为 posit 类型,将它们相加,并将结果转换回 float32 类型。一旦注册了 posit 类型,TVM 就可以解析特殊的 dtype 语法 custom[<typename>],其中 <typename> 是为该类型注册的名称。此语法还支持常用的 <bits>x<lanes> 格式;在这里,我们使用 16 来指示每个 posit 的宽度为 16 位。(lane 的数量默认为 1。)
降低函数注册
虽然 TVM 可以解析上面的程序,但它还不能编译它,因为 TVM 还不理解如何编译 posit 类型上的操作。为了编译这些程序,我们为自定义数据类型注册降低函数,这有助于 TVM 将操作转换为它可以理解和编译的内容。
通常,不期望用户直接将操作降低到 LLVM 或 CUDA。相反,大多数使用自定义数据类型的代码都可以降低为不使用自定义数据类型的代码,并使用一些简单的技巧。然后,我们可以依靠原生 TVM 来理解和编译代码。
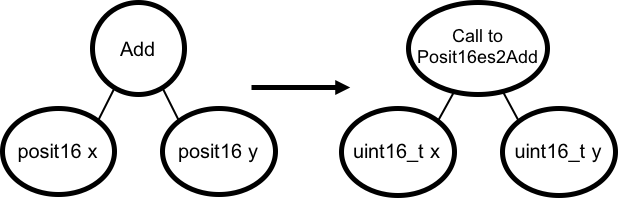
图 1 显示了一种常见模式。假设我们对探索 posit 类型感兴趣,并选择通过自带数据类型框架将 posit 模拟库(例如 Stillwater Universal)插入 TVM 来运行一些工作负载。我们的工作负载是一个简单的程序,它将两个 posit 输入相加。原生 TVM 不理解如何实现 posit 加法——但这没有必要,因为我们有一个库实现了我们的数据类型!该库包含 posit 加法的实现,以及其他运算符,如乘法和平方根。为了实现这种 posit 加法,我们只想调用我们的库。因此,我们的 Add 节点应该变成一个 Call 节点,调用我们库中的一个函数(称之为 Posit16es2Add)。为了在 TVM 可以理解的类型中存储输入 posit 的位,我们使用 16 位无符号整数。生成的程序是 TVM 可以理解和编译的程序——它只是对外部库函数的调用,接受两个无符号整数。
为了实现上述降低,我们为 posit 注册一个降低函数
tvm.target.datatype.register_op(
tvm.target.datatype.create_lower_func({16: 'Posit16es2Add'}),
'Add', 'llvm', 'posit')
上面的代码为特定的运算符(Add)、编译目标(LLVM)、数据类型(posit)和位长(16)注册了一个降低函数。第一个参数是降低函数。这可以是任何接受 TVM IR 节点并返回新的 TVM IR 节点的函数。在我们的例子中,我们使用了自带数据类型框架提供的辅助函数。tvm.target.datatype.create_lower_func({16:'Posit16es2Add'}) 为上面描述的常见模式创建了一个降低函数。生成的函数将给定节点的参数转换为 uint16_t,然后将节点本身转换为对给定函数名称的调用(在本例中,对于位长为 16 的 posit,函数名称为 'Posit16es2Add')。我们将字典传递给 create_lower_func,以便 TVM 可以根据数据类型的位长调度到适当的函数名称。
为了实现自定义数据类型,用户需要为他们想要运行的工作负载中的每个运算符注册一个降低函数。对于像 ResNet 这样的网络,这将大约需要 10 个运算符,包括 Add、Div、各种 Casts 和 Max 等。在我们的测试中,注册数据类型和所有降低函数大约需要 40 行 Python 代码。一旦注册了所有需要的运算符,自定义数据类型工作负载就可以像任何其他 TVM 程序一样轻松运行!
总结
自带数据类型框架将用户定义的数据类型引入 TVM。我们希望这将鼓励数据类型研究人员在其研究中使用 TVM;同样,我们希望这将激发深度学习社区对自定义数据类型的兴趣。有关自带数据类型框架的更多文档,请访问 TVM 自带数据类型开发者教程。
Gus Smith 是华盛顿大学的博士生,与 Luis Ceze 和 Zachary Tatlock 在计算机体系结构和编程语言的交叉领域合作。他的网站是 justg.us。
Andrew Liu 是华盛顿大学的本科生,也是 UW CSE SAMPL 和 PLSE 实验室的成员。
参考文献
-
Jouppi, Norman P., et al. “张量处理单元的 In-datacenter 性能分析。” 第 44 届计算机体系结构国际研讨会论文集. 2017. ↩